The Markdown Layer: How Four Plain Text Files Quietly Became Claude's Operating System
A working field guide to CLAUDE.md, SKILL.md, MEMORY.md, and AGENTS.md — the unglamorous files that now run your AI.

Every serious Claude user eventually hits the same wall. You explain your stack, your conventions, your taste. You get good output. You start a new session — and explain it all over again.
The fix isn't a better prompt. It's a file.
A small family of Markdown files now sits between you and the model. They carry context across sessions, package expertise into reusable capabilities, and let agents act with judgment instead of guesswork. Plain text. A handful of rules. This is the working guide.
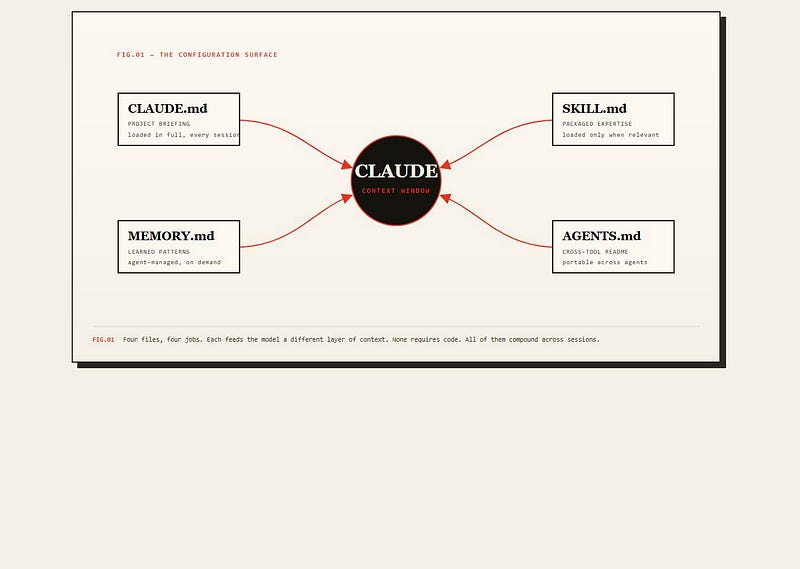
01 — The Project Briefing: CLAUDE.md
CLAUDE.md is the brief Claude reads before it touches your code. Put it at the project root and Claude Code loads it automatically, prepending it to the system prompt for every session in that directory. No special syntax. No @imports required at the root. Just the file.
Use it for what is true about this project: tech stack, code style, the test command, the deploy command, the conventions that aren't optional. You can also place CLAUDE.md in subdirectories — it's loaded on demand when files in that directory enter context. Personal preferences belong in ~/.claude/CLAUDE.md, which applies across all your projects.
There is a useful subtlety here. Anthropic's own guidance is to keep these files short and to refine them like prompts. Every line costs tokens and competes for attention. The discipline is to write only what changes behavior.
02 — Packaged Expertise: SKILL.md
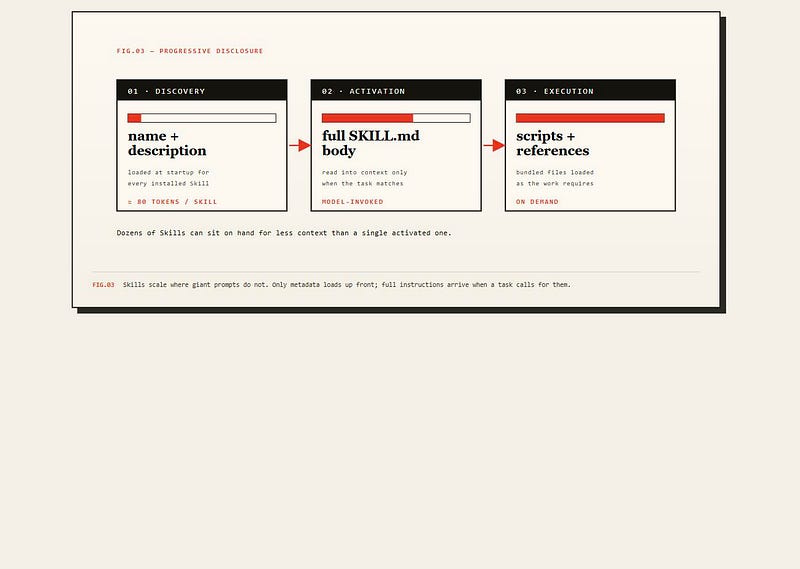
SKILL.md is for capability, not context. A Skill is a folder containing a SKILL.md file with YAML frontmatter (name, description) and optional supporting files — scripts, references, templates. Claude discovers Skills by reading just the metadata, then loads the body only when the task matches.
The mechanism underneath is progressive disclosure, in three layers. Layer 1: name and description, always preloaded, ~100 tokens per Skill. Layer 2: the SKILL.md body, loaded when Claude judges the Skill relevant, under a 5,000-token budget. Layer 3: bundled files and executable scripts, loaded on demand. The result: a Skill library can grow large without growing your active context.

The open standard: agentskills.io defines an interoperable Skill format. The same Skill can run across Claude, Cursor, ChatGPT, OpenCode, Gemini, and others. The repository pattern: skills/ at the root, one subfolder per Skill, with SKILL.md inside. Version it like code. Review it like code.
03 — What the Agent Learns: Memory files
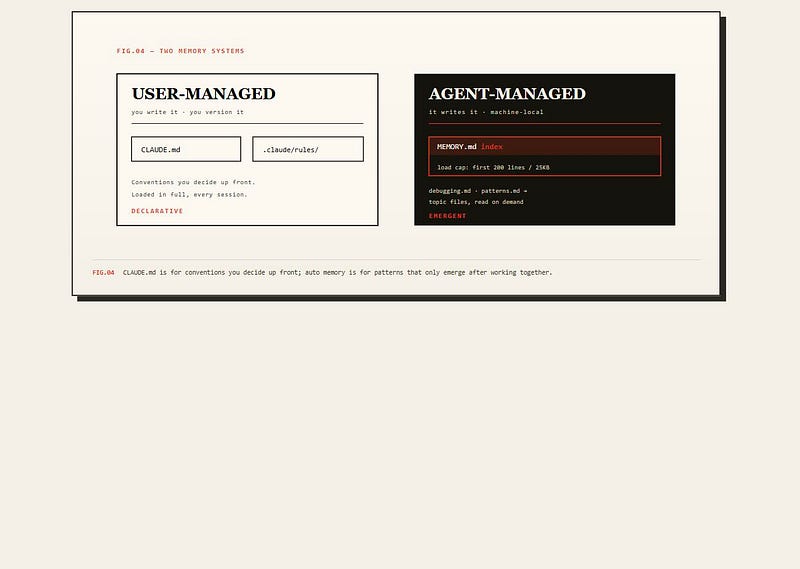
This is where most people get confused, so be precise. There are two memory systems, and they behave differently.
User-managed files are the ones you write: CLAUDE.md and rules under .claude/rules/. You edit them, you commit them, the team reads them. They define how the agent should behave.
Auto memory is /MEMORY.md — what Claude remembers about you, automatically. Whenever a session ends, Claude can persist takeaways: your preferred libraries, debugging style, recurring patterns. MEMORY.md is read at the start of every conversation, anything beyond is read on demand. To stay under the cap, Claude moves detail into topic files like debugging.md or patterns.md. Auto memory is machine-local and not shared across machines or cloud. You manage it with the /memory command; the old # inline shortcut has been discontinued.
On the API, the memory tool generalizes the idea. Claude can create, read, update, and delete files in a /memories directory that persists between sessions, building knowledge without holding everything in context. One honest caveat ships with it: memories are point-in-time observations, not live state. Claims about code behavior can go stale.
04 — The Cross-Tool README: AGENTS.md
AGENTS.md answers a different question: what if you use more than one agent? It's an open, vendor-neutral format — a single Markdown file at the repository root that any compatible agent reads on task start.
It's read natively by Codex, Cursor, Copilot, Gemini CLI, Aider, Windsurf, Zed, Factory, Jules, and more than twenty other tools. It's stewarded by the Linux Foundation's Agentic AI Foundation, and has been adopted by more than 60,000 repositories. The point is to avoid maintaining a separate context file per tool: one canonical source, referenced where needed.
It pairs cleanly with everything above. AGENTS.md is project-scoped context; Agent Skills are reusable, portable capabilities. Complementary, not competing.
05 — The Discipline: Six Rules That Actually Work
01. Treat the file as a behavioral contract, not documentation. Every line should change how the agent acts. If it doesn't, delete it.
02. Don't pay for what the agent learns in one session. If Claude finds your test utilities on its own, you don't need a line about them.
03. Let tools be the constraint. If a linter, formatter, type checker, or CI gate can enforce a rule, don't restate it in prose.
04. Resolve conflicts explicitly. "Move fast" and "run the full suite before every commit" can't both win. When priority is unstated, models skip verification and rush to code.
05. Write triggers, not vibes. "Handle errors gracefully" is human guidance. "Run alembic check before migrations; abort if a downgrade path is missing" is an agent instruction.
06. For Skills, invest in the description. It drives automatic selection. State plainly what the Skill does and when to use it.
The empty file that does nothing. The bloated file the agent half-reads. The duplicated rule that already lives in your linter. The conflicting directives with no priority. The vague "be thoughtful" that does nothing. Each is a cost paid every session.
The Working Stack
A clean setup for a serious project looks like this:
CLAUDE.mdat the repo root: ~30 lines on stack, style, commands, and the rules that must be followedAGENTS.mdat the repo root if the team uses more than one coding agentskills/for repeatable capabilities, withSKILL.mdper Skill, descriptions tuned for selection- Personal
~/.claude/CLAUDE.mdfor individual preferences that should not pollute the repo /memoryreviewed occasionally; stale entries removed; topic files used as it grows- API memory tool for agents that need persistent state across sessions
Plain text. A handful of rules. A model that finally remembers what it's doing.
This piece draws on official Anthropic documentation (CLAUDE.md, Claude Code best practices, memory architecture, Agent Skills), the agentskills.io open standard, and the agents.md project.



